
Commons-Collections7原理分析
CC7 依旧是寻找 LazyMap 的触发点,这次用到了 Hashtable。
reconstitutionPut#hashCode版
前置知识
Hashtable
Hashtable 与 HashMap 十分相似,是一种 key-value 形式的哈希表,但仍然存在一些区别:
HashMap继承AbstractMap,而Hashtable继承Dictionary,可以说是一个过时的类。- 两者内部基本都是使用“数组-链表”的结构,但是
HashMap引入了红黑树的实现。 Hashtable的key-value不允许为null值,但是HashMap则是允许的,后者会将key=null的实体放在index=0的位置。Hashtable线程安全,HashMap线程不安全。
Hashtable 的 readObject 方法中,最后调用了 reconstitutionPut 方法将反序列化得到的 key-value 放在内部实现的 Entry 数组 table 里。
然后发现 reconstitutionPut 调用了 key 的 hashCode 方法。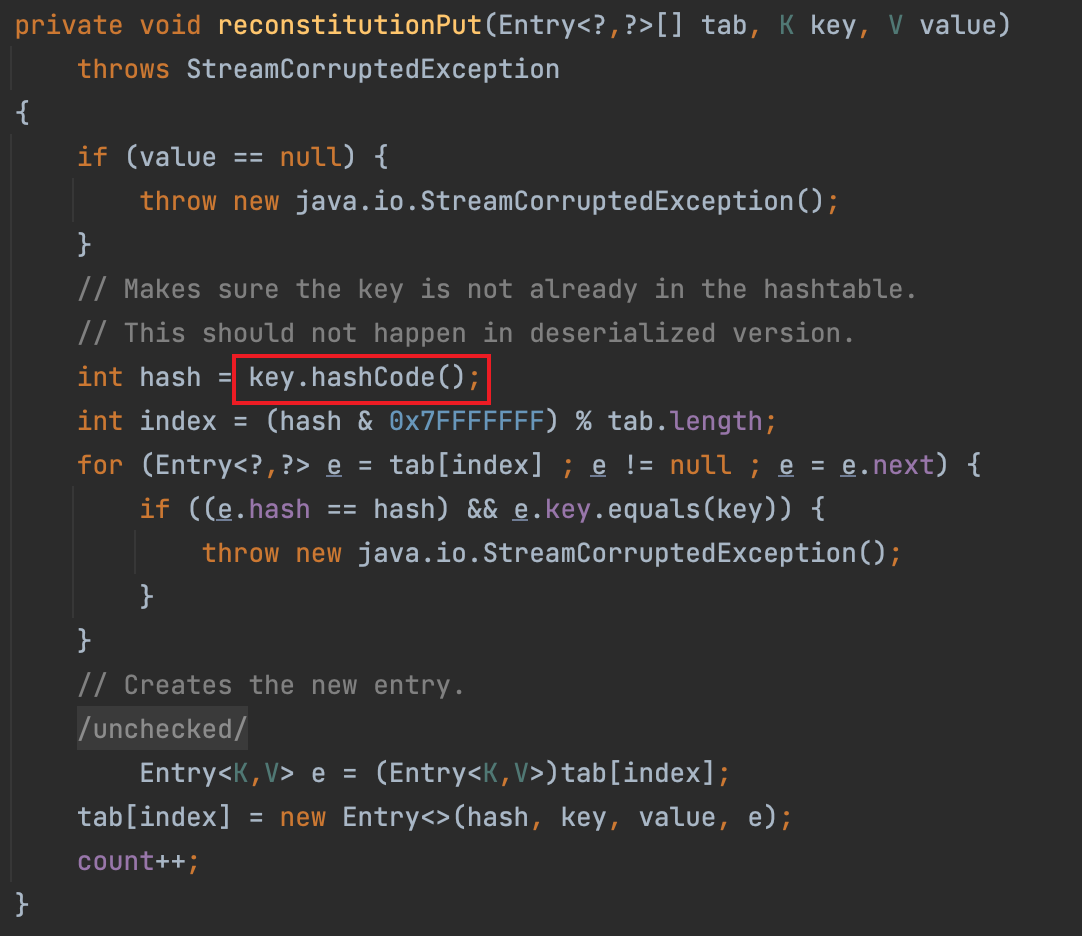
POC
1 | public class CC7 { |
总结
利用说明:
- 用
Hashtable代替HashMap触发LazyMap方式,与CC6 HashMap几乎一致。Gadget总结:调用链展示:1
2
3kick-off gadget:java.util.Hashtable#readObject()
sink gadget:org.apache.commons.collections.functors.InvokerTransformer#transform()
chain gadget:org.apache.commons.collections.keyvalue.TiedMapEntry#hashCode()依赖版本1
2
3
4
5
6Hashtable.readObject()
TiedMapEntry.hashCode()
LazyMap.get()
ChainedTransformer.transform()
ConstantTransformer.transform()
InvokerTransformer.transform()commons-collections : 3.1
ysoserial版
前置知识
首先梳理清楚 Map、AbstractMap、HashMap 这三者的关系,如上图所示HashMap 继承 AbstractMap 同时这二者实现Map接口。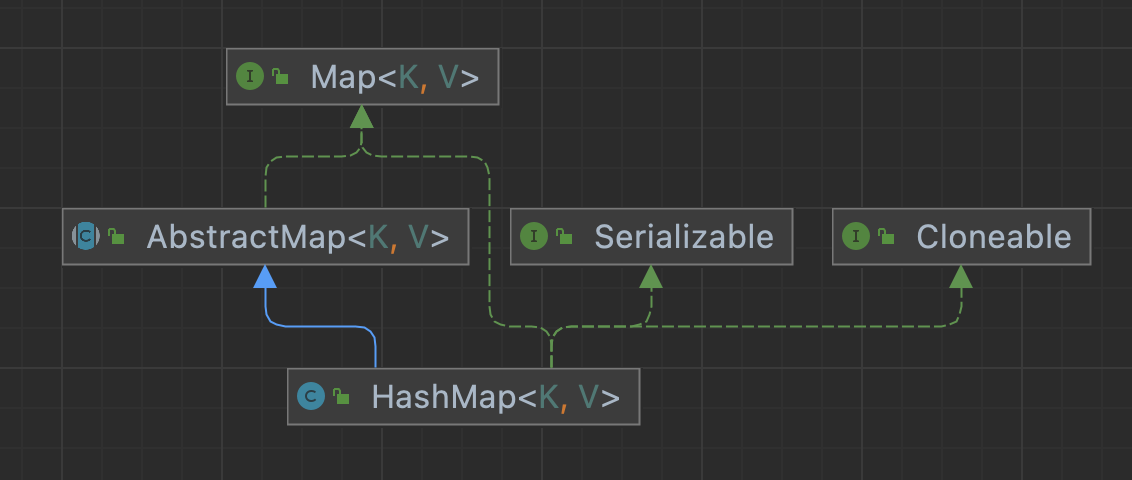
Map接口中的方法如下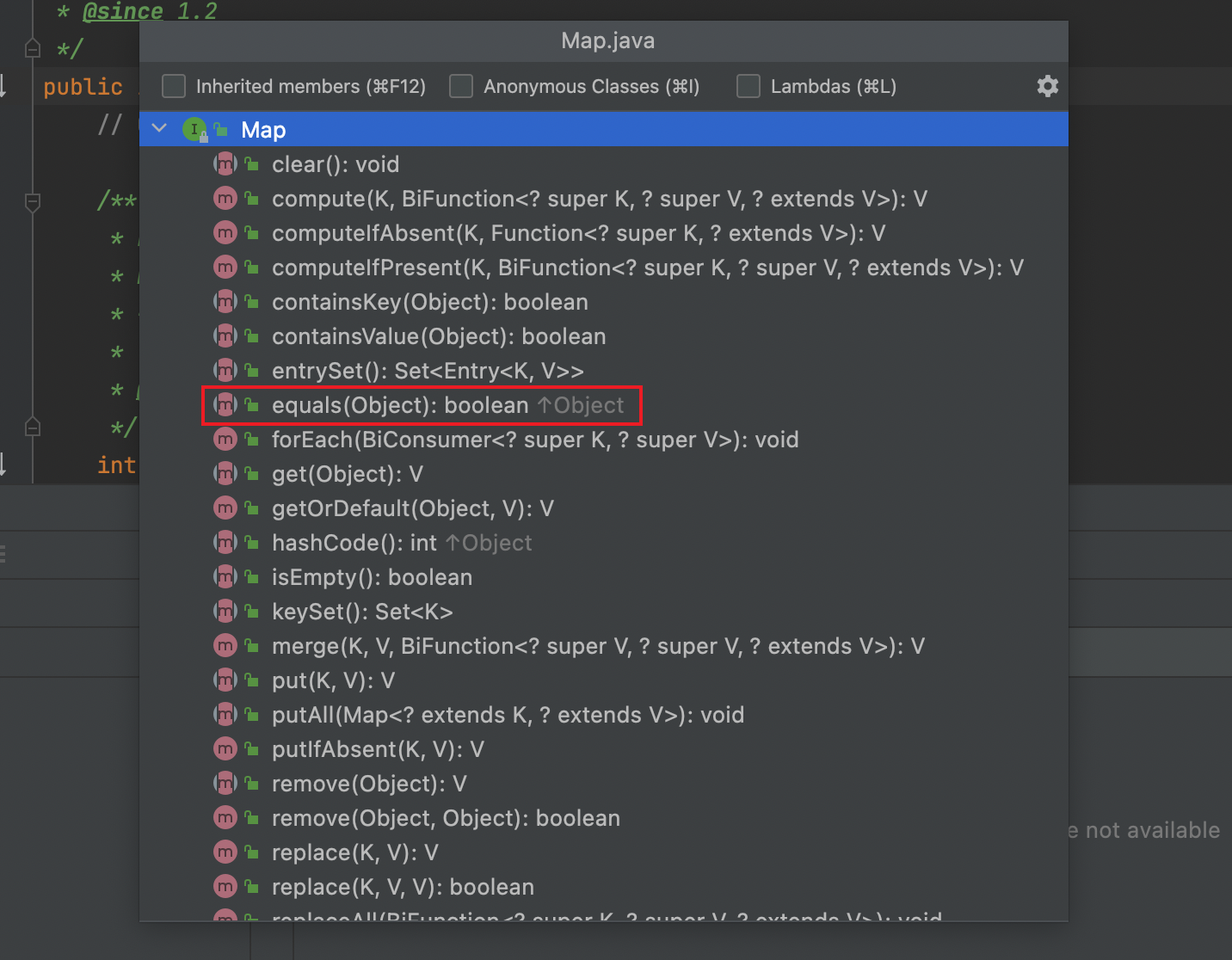
重点关注equals方法,这个方法在HashMap的父类AbstractMap中实现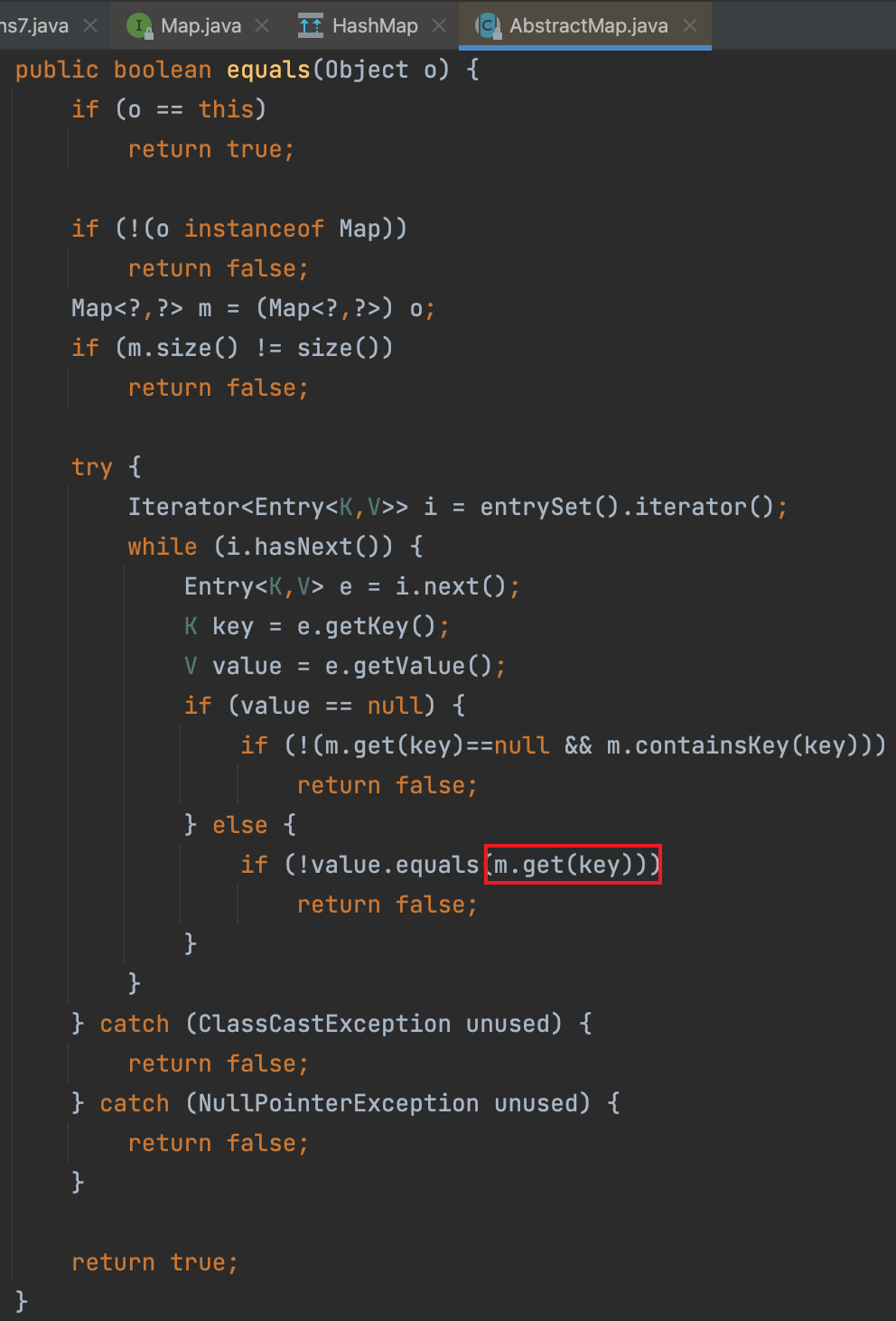
该函数会调用map的get方法,然而LazyMap正好实现Map接口,因此在这里可以有所作为。
但是触发这个是有条件的,以下三个判断都不能进入,否则代码执行不到触发点。
1 | if (o == this) |
链分析
反序列化入口是 Hashtable 的readObject函数
1. readObject函数分析
1 | private void readObject(java.io.ObjectInputStream s) |
在readObject中会把元素通过读取对象的形式还原出来,并通过reconstitutionPut进行元素对比加入到hashtable中。
2. 与LazyMap的连接点
1 | private void reconstitutionPut(Entry<K,V>[] tab, K key, V value) |
e.key.equals(key)这里是完美的衔接点,它实现了将hashtable和LazyMap之间反序列化的连接。
POC
主要步骤如下:
- 创建两个
hashmap和两个Lazymap - 向
lazymap中填充以yy和zZ为key的两个键值对 - 将两个
lazymap put进创建的hashtable中 - 修改
transformerChain的iTransformers属性为命令执行链 - 删除
lazyMap2中多余的key
1 | public class CommonsCollections7 extends PayloadRunner implements ObjectPayload<Hashtable> { |
借用D4ck师傅的构造链图 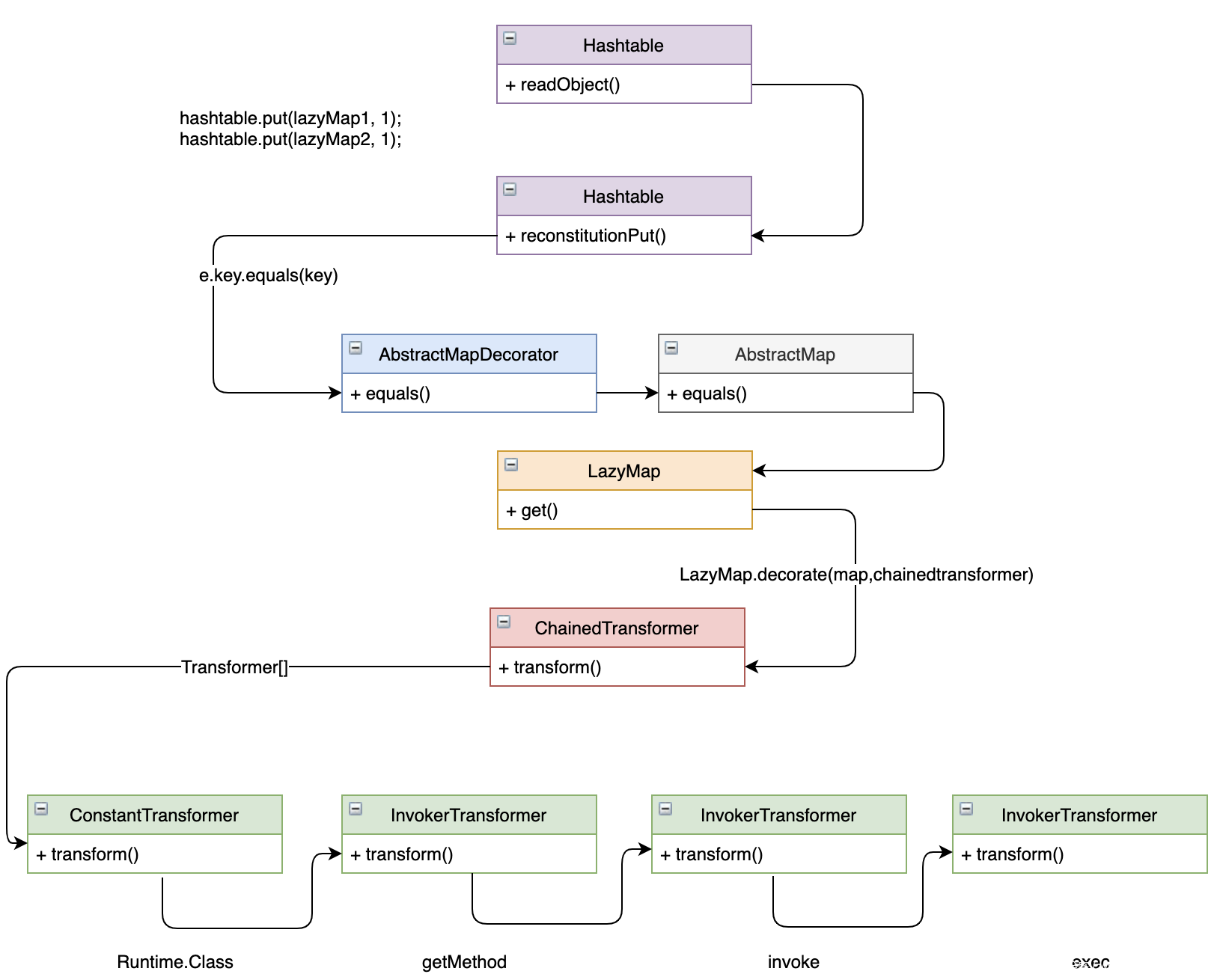
问题分析
1. 为什么innerMap为HashMap?
在构造LazyMap时 HashMap 作为decorate参数的第一个参数,那么这里为什么要使用HashMap呢,如果不认真分析这点很容易被忽略。因为要使用的是HashMap中的equals方法,那么这个传递关系如下图所示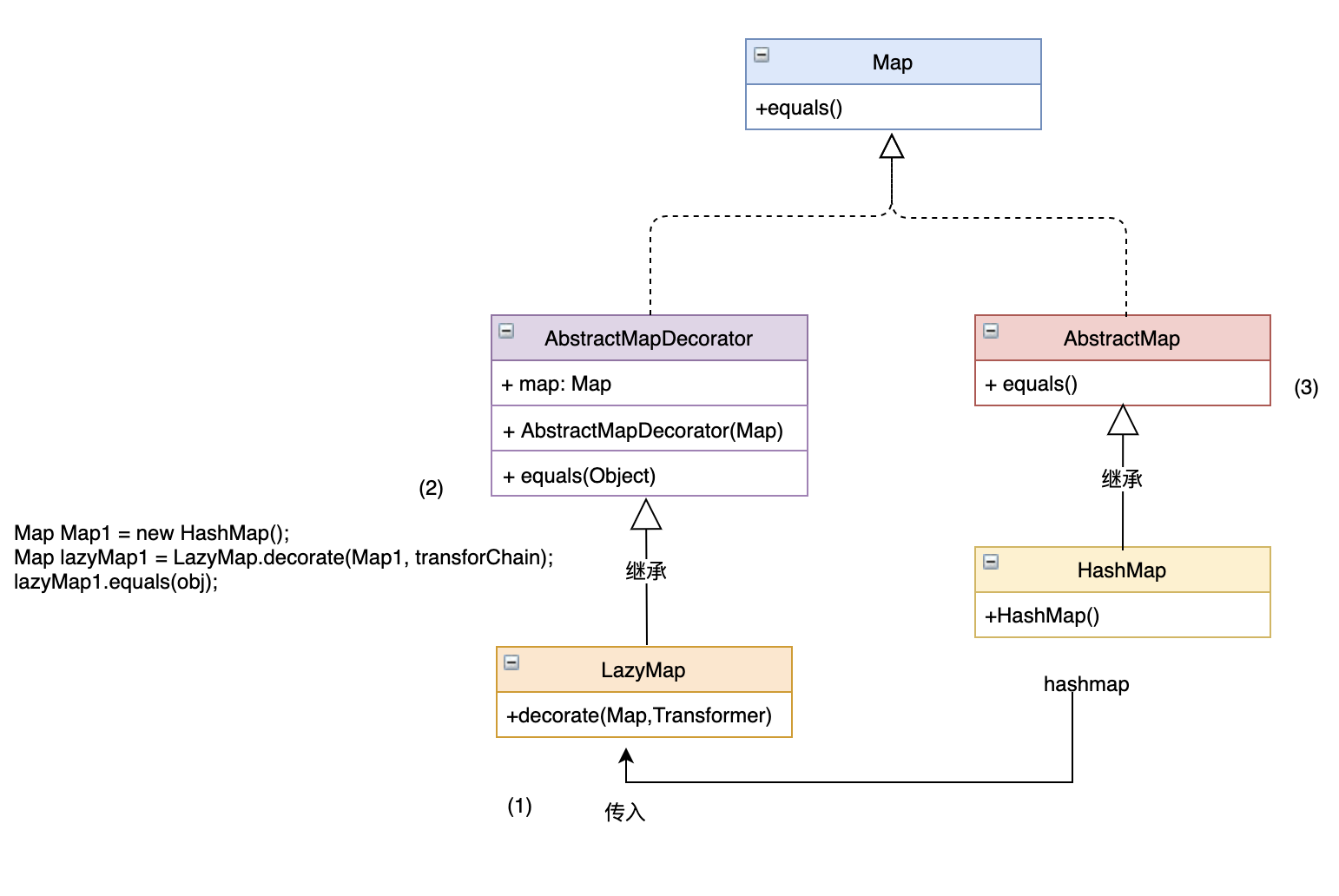
向LazyMap传入Hashmap后在lazymap比较时会调用第一个map的equal方法,同时hashmap继承了AbstractMap类但没有重写equals方法,所以最终调用的是AbstractMap类中的equals方法,这也是为什么传入hashmap的原因。
2. 为什么创建两个不同的hashmap作为参数?
如果两个hashmap相同的话会直接在hashtable put的时候认为是一个元素,所以之后就不会在反序列化的时候触发equals代码
3. 为什么选择 yy 和 zZ 作为key?
首先它俩的hashCode相等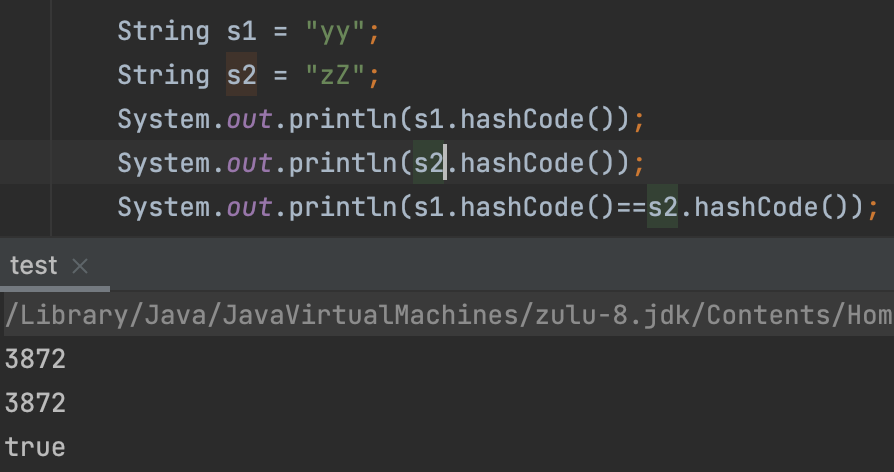
这里我们回头看下Hashtable中的reconstitutionPut方法,重点看equals函数调用的前提条件是e.hash和hash相等,那就意味着两个key的hash必须相同,这个是条件之一。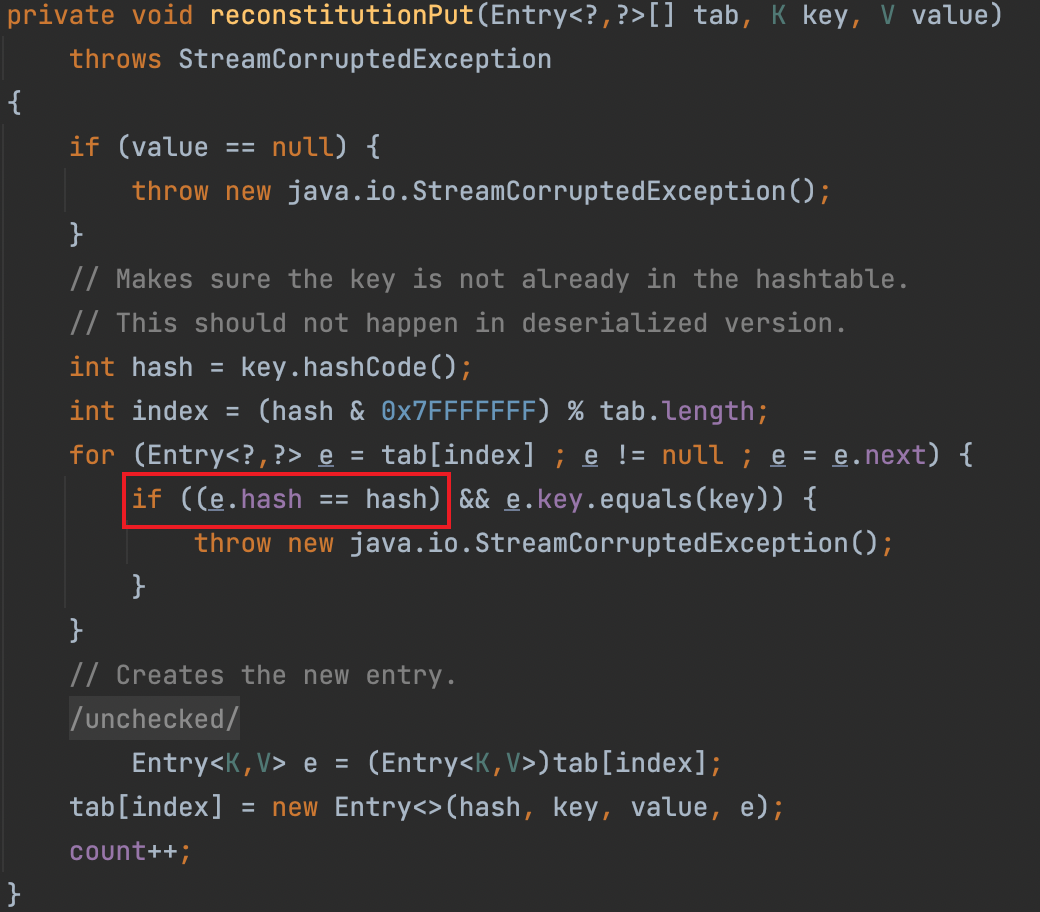
那为什么不能把两个key设成一样的呢?这样hash就相等了,但是如果继续往下跟代码的话就会发现在lazymap的get方法中有以下逻辑,map的key不能重复否则就不会执行transform函数执行代码了。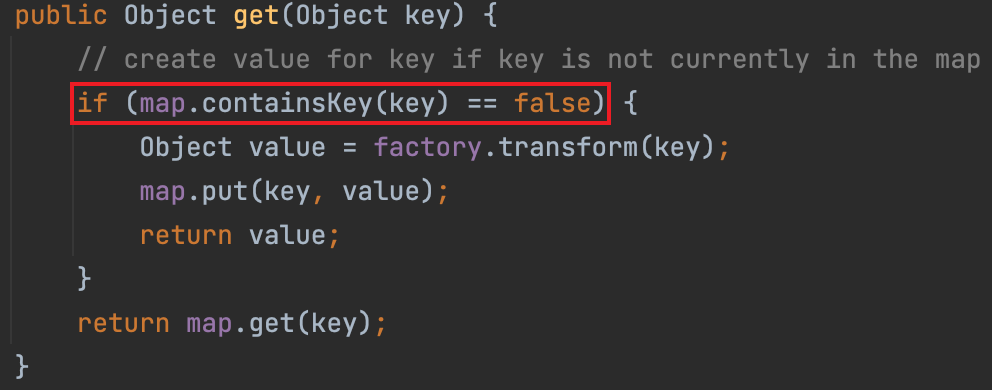
4. 为什么要移除第二个LazyMap中的元素?
hashtable在添加第二个元素之前,可以看到innerMap1和innerMap2的size都是1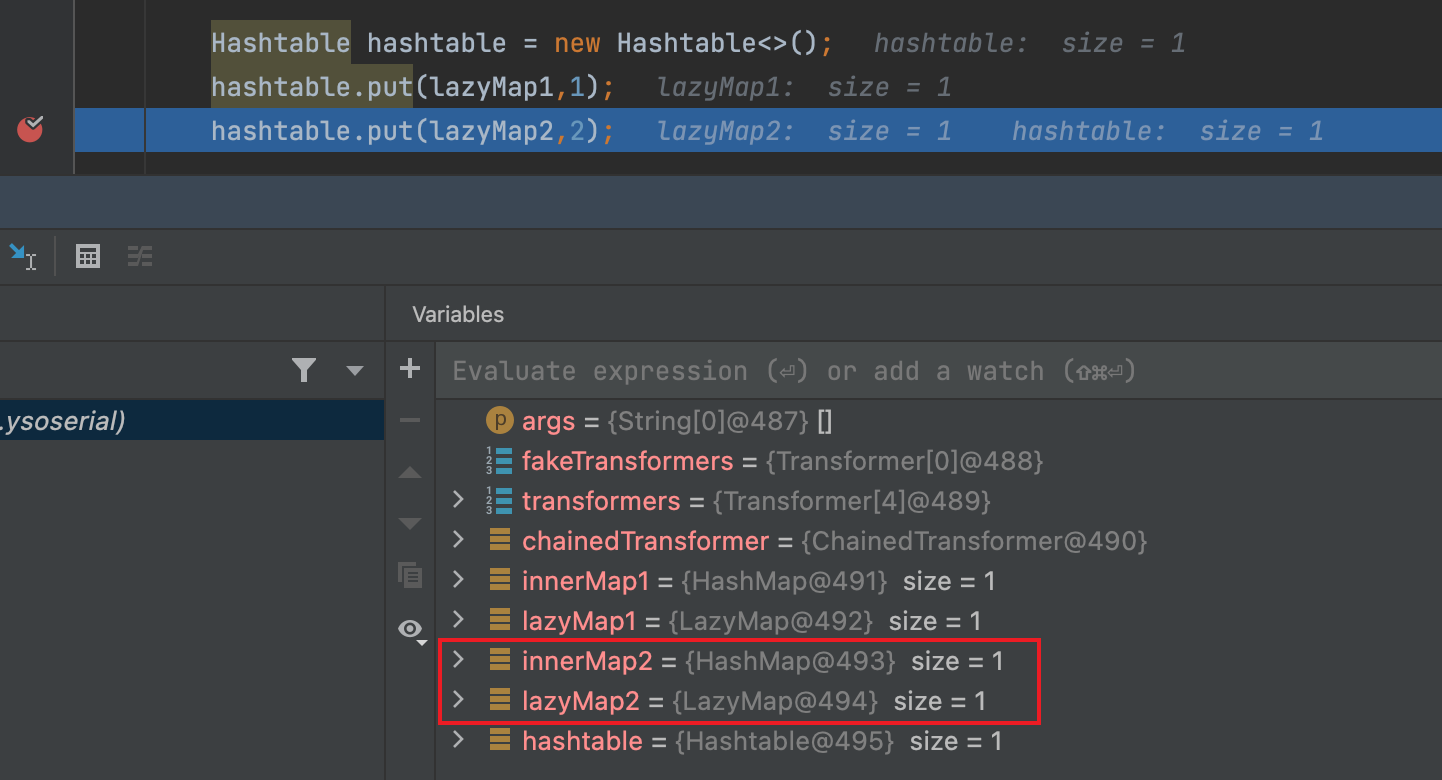
hashtable.put会触发equals方法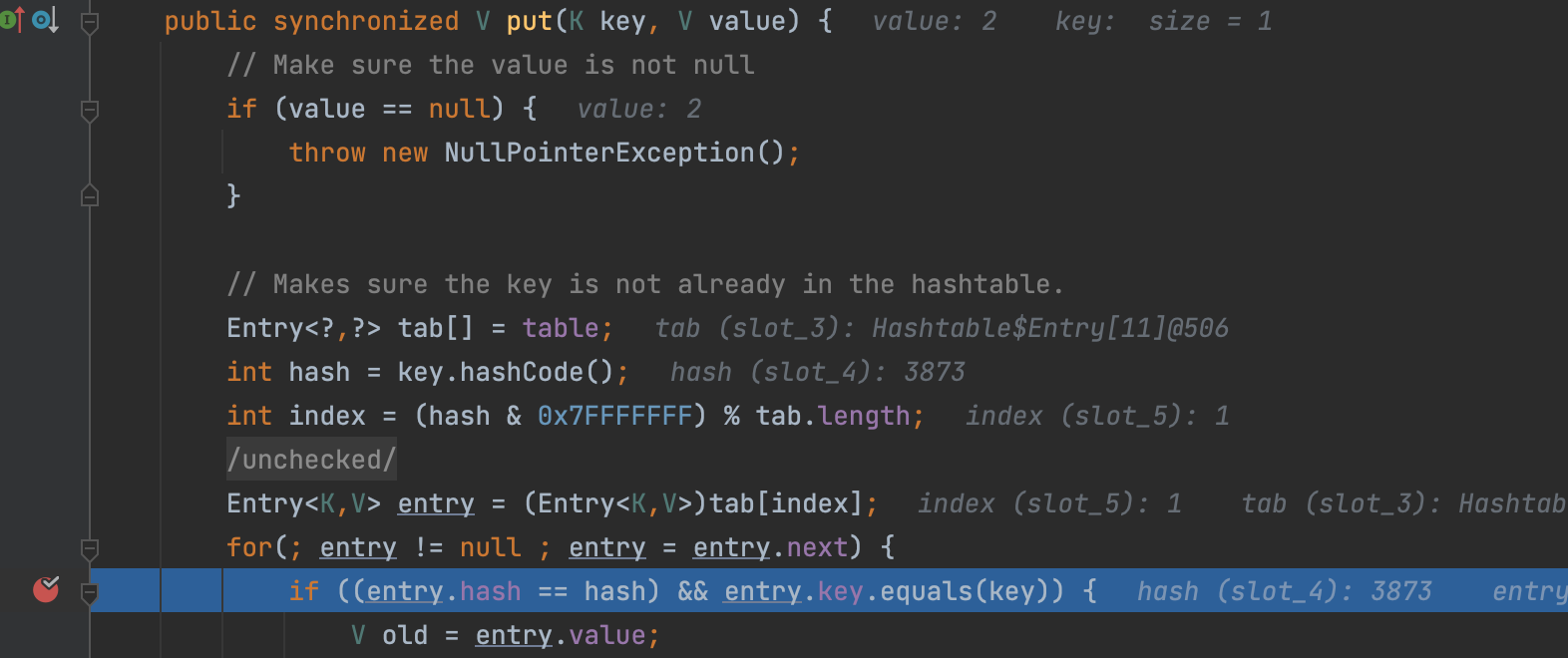
equals会进入LazyMap的get方法,把yy放进去
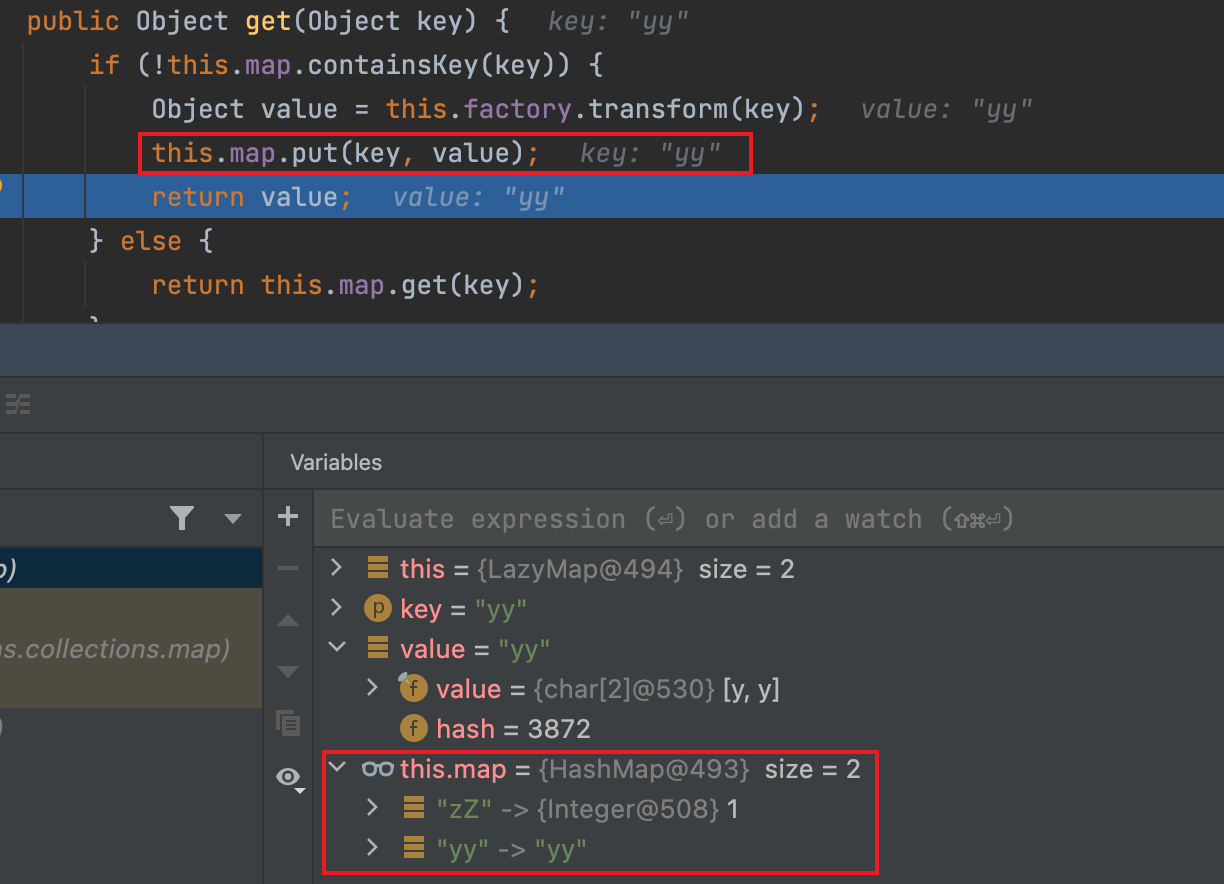
从而lazyMap2变成了两个元素。
这导致在后面运行到AbstractMap的equals方法时出现新问题
其中,第三个判断的m.size()=2,size()=1,直接返回false 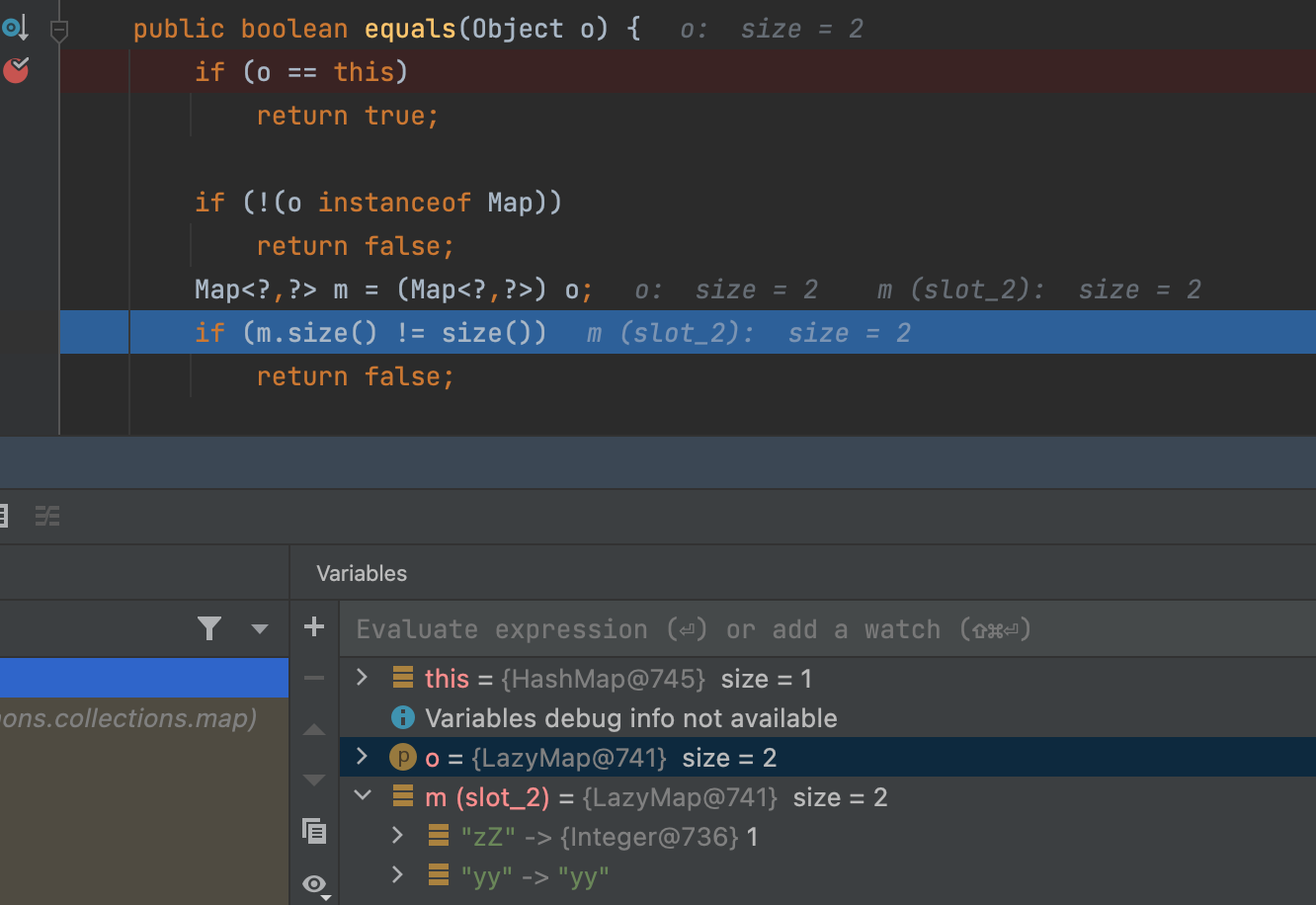

移除LazyMap2中的yy后,m.size()=1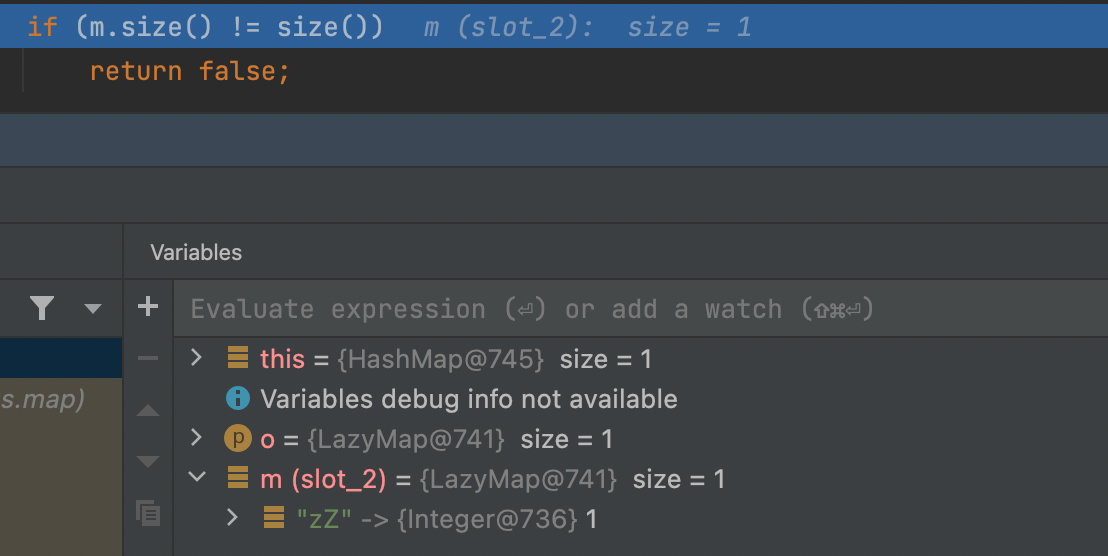
总结
利用了hashtable反序列化时会触发元素比较,巧的是lazymap的equals方法是继承父类方法,父类做的操作是用lazymap的innermap进行对比,刚好innermap是hashmap,hashmap的equals方法时继承AbstractMap类,其中有个获取equals方法参数的key,即m.get(key)。